

Китайський стартап у галузі штучного інтелекту DeepSeek представив свою нову розробку — DeepSeek-R1, модель штучного інтелекту з відкритим кодом, яка за продуктивністю не поступається передовій моделі OpenAI o1 у задачах з математики, програмування та міркування, при цьому коштує на 90–95% дешевше, повідомляє VentureBeat
DeepSeek-R1 анонсована разом із публікацією ваг моделі на платформі Hugging Face за ліцензією MIT, є значним кроком вперед для відкритих технологій штучного інтелекту та потенційно вирівнює умови у глобальній гонці досягнення штучного загального інтелекту (AGI).
DeepSeek-R1, побудована на базі іншої моделі DeepSeek V3, показала високі результати у тестах:
- 79,8% у математичному конкурсі AIME 2024 (порівняно з 79,2% в o1);
- 97,3% на тесті MATH-500 (96,4% в o1);
- Рейтинг 2,029 на Codeforces, що перевищує результати 96,3% людських програмістів.
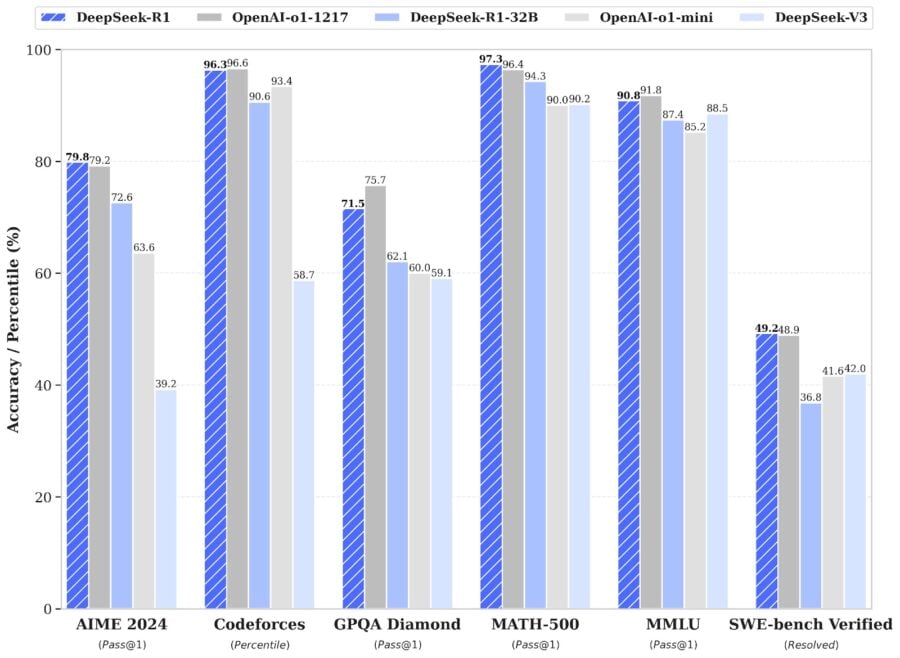
Хоча OpenAI o1 трохи випередила у загальних знаннях (91,8% точності проти 90,8% у DeepSeek-R1 на тесті MMLU), модель DeepSeek продемонструвала сильні можливості у складному міркуванні та програмуванні, що є важливим досягненням для китайського сектору штучного інтелекту.
При цьому DeepSeek-R1 значно знижує витрати на використання. Якщо OpenAI o1 коштує $15 за мільйон вхідних токенів і $60 за мільйон вихідних токенів, то DeepSeek Reasoner API, заснований на моделі R1, пропонує $0,55 за мільйон вхідних токенів і $2,19 за мільйон вихідних токенів.
Ця цінова перевага у поєднанні зі співставною продуктивністю може зробити DeepSeek привабливим вибором для розробників і бізнесу, які шукають ефективні ШІ-інструменти.
Розробка DeepSeek-R1 почалася з DeepSeek-R1-Zero, моделі, навченої виключно за допомогою підкріплювального навчання (RL). Завдяки процесу проб і помилок модель самостійно навчилася складних способів міркування, досягнувши 86,7% точності у тесті AIME 2024, що відповідає результатам OpenAI o1-0912.
Однак ранні версії стикалися з проблемами, такими як мовні змішування та погана читабельність. DeepSeek розвʼязав ці питання за допомогою багатоступеневого підходу:
- Тонке налаштування базової моделі DeepSeek-V3 за допомогою стартових даних;
- RL-навчання для задач міркування;
- Перенавчання із використанням супервізованих даних із різних доменів, таких як фактичні запитання й відповіді та самоусвідомлення.
У результаті була створена вдосконалена модель DeepSeek-R1, яка поєднує передові можливості міркування з покращеною читабельністю та функціональністю.
Випуск DeepSeek-R1 загалом показує зростання конкурентоспроможності відкритих моделей ШІ. Завдяки дистиляції своєї технології у менші моделі DeepSeek показала здатність підвищувати продуктивність у масштабах. Наприклад, дистильована модель Qwen-1.5B перевершила більші моделі GPT-4o та Claude 3.5 Sonnet у математичних тестах.
Крім того, весь процес розробки — включаючи дані для навчання та методології — є відкритим, що сприяє прозорості та співпраці у сфері досліджень штучного інтелекту.
DeepSeek демонструє R1 на своїй платформі DeepThink, яка нагадує ChatGPT, а також пропонує ваги моделі, репозиторій коду та інтеграцію через API.